
Contest
The Guess The Age (GTA) contest is an international competition among methods based on modern Deep Convolutional Neural Networks (DCNNs) for age estimation from facial images. In order to allow the participants to train effective models, we provide a dataset, the Mivia Age Dataset, including 575.073 images annotated with age labels; it is among the biggest publicly available datasets of faces in the world with age annotations. The performance of the proposed methods will be evaluated in terms of accuracy and regularity on a test set of more than 150.000 images, different from the ones available in the training set.

Age estimation from face images is nowadays a relevant problem in several real applications, such as digital signage, social robotics and business intelligence. In the era of deep learning, many DCNNs for age estimation have been proposed, so effective to achieve performance comparable to those of humans.
To this concern, it is worth pointing out that the most promising methods use ensembles of DCNNs, making the obtained classifier not usable in real applications, as they require prohibitive computational resources not always available; in addition, their training procedure is made complex by the plurality of neural networks and typically require huge training sets not simply collectable.
Within this framework, we propose the usage of a new huge dataset, the MIVIA Age Dataset, and we restrict the competition to methods based on a single neural network. Having a wide dataset, the participants are free to propose novel DCNN architectures or to define innovative training procedures for standard DCNN architectures.
Dataset
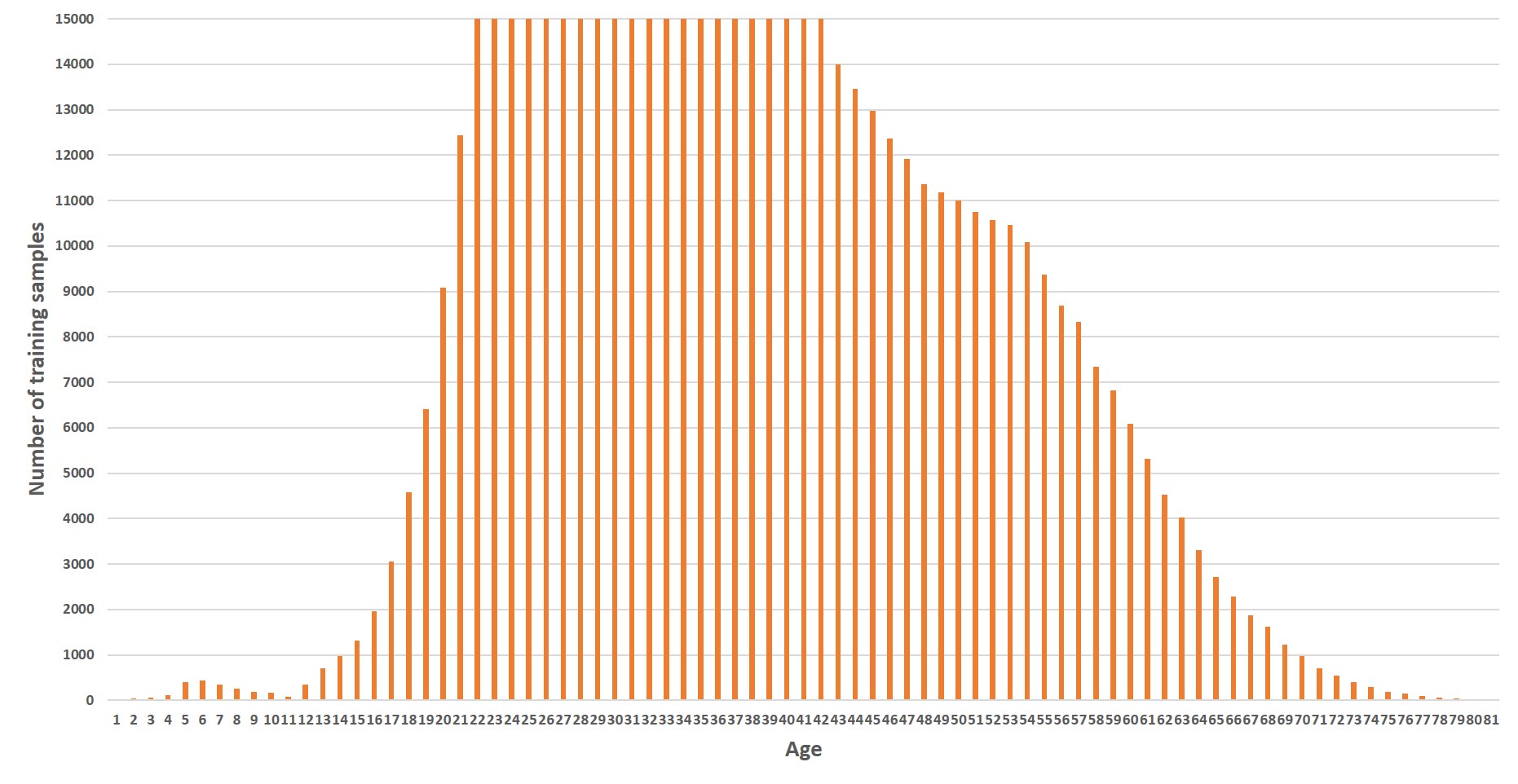
The MIVIA Age Dataset is composed of 575.073 images of more than 9.000 identities, got at different ages.
They have been extracted from the VGGFace2 dataset and annotated with age by means of a knowledge distillation technique, making the dataset very heterogeneous in terms of face size, illumination conditions, facial pose, gender and ethnicity.
The distribution of the dataset samples over the age is depicted on the left. Each image of the dataset contains a single face, already cropped.
We make available to the participants an archive with all the training samples and a CSV file with the age annotations.
Evaluation protocol
The methods proposed by the participants, trained on the set provided for the competition, will be evaluated in terms of accuracy and regularity on a private test set; an index called Age Accuracy and Regularity $AAR$ is introduced for taking into account accuracy and regularity in a single performance index.
In particular, the evaluation of accuracy is carried out by means of Mean Absolute Error $MAE$ on the entire test set. If $K$ is the number of samples in the test and denoted $p_i$ the age prediction of a method for the i-th sample of the test set and the $r_i$ real age label, the absolute age estimation error on the i-th sample is:
$e_i=|p_i-r_i|$
Of course, the lower is the $MAE$ achieved by a method, the higher is its accuracy. Starting from AI, the $MAE$ is computed as the average age estimation error over all the $K$ samples of the test set:
$ MAE=\sum_{i=1}^K \frac{e_i}{K} $
The regularity over different age groups is measured by means of standard deviation $\sigma$, according to the following rule:
$ \sigma=\sqrt{\frac{\sum_{j=1}^8(MAE^j-MAE)^2}{8}} $
Where:
- $MAE^1$ is computed over the samples whose real age is in the range 1-10
- $MAE^2$ is computed over the samples whose real age is in the range 11-20
- $MAE^3$ is computed over the samples whose real age is in the range 21-30
- $MAE^4$ is computed over the samples whose real age is in the range 31-40
- $MAE^5$ is computed over the samples whose real age is in the range 41-50
- $MAE^6$ is computed over the samples whose real age is in the range 51-60
- $MAE^7$ is computed over the samples whose real age is in the range 61-70
- $MAE^8$ is computed over the samples whose real age is in the range 70+
The final score is the Age Accuracy and Regularity $AAR$ index, computed as follows:
$ AAR=max(0; 7-MAE)+max(0; 3-\sigma) $
The $AAR$ index can assume values between 0 and 10, weighting 70% the contribution of $MAE$ (accuracy) and 30% the contribution of $\sigma$ (regularity). Methods which achieve $MAE\geq7$ and $\sigma\geq3$ will obtain $AAR=0$. A perfect method, obtaining $MAE=0$ and $\sigma=0$ will achieve $AAR=10$. Methods which achieve intermediate values of $MAE$ and $\sigma$ obtain intermediate values of $AAR$.
The method which achieves the highest $AAR$ will be the winner of the contest.
Rules
- The deadline for the submission of the methods is 30th June, 2021. The submission must be done with an email in which the participants share (directly or with external links) the trained model, the code and the report. Please follow the detailed instructions reported here.
- The participants can receive the training set and the age annotations by sending an email to the organizer, in which they also communicate the name of the team.
- The participants can use only the received samples for training and validation, without the possibility to take samples from other datasets. Additional samples of ages less represented in the dataset can be obtained with data augmentation techniques, which are encouraged both for extending the training set and for increasing its representativeness.
- The participants can use as DCNNs only single neural networks, not ensembles. They are free to design novel architectures or to define novel training procedure and loss functions for classifiers or regressors. Particularly interesting are methods which exploit the ordinal ranking between the age groups.
- The participants must submit their trained model and their code by carefully following the detailed instructions reported here.
- The participants must produce a brief PDF report of the proposed method, by following a template that can be downloaded here.
Instructions
The methods proposed by the participants will be executed on a private test set. To leave the participants totally free to use all the software libraries they prefer and to correctly reproduce their processing pipeline, the evaluation will be done on Google Colab (follow this tutorial) by running the code submitted by the participants on the samples of our private test set.
Therefore, the participants must submit an archive (download an example) including the following elements:
-
A Python script
test.py, which takes as inputs a CSV file with the same format of the training annotations (--data) and the folder of the test images (--images) and produces as output a CSV file with the predicted age for each image (--results). Thus, the script may be executed with the following command:
python test.py --data foo_test.csv --images foo_test/ --results foo_results.csv -
A Google Colab Notebook
test.ipynb, which includes the commands for installing all the software requirements and executes the scripttest.py. - All the files necessary for running the test, namely the trained model, additional scripts and so on.
The provided sample test.py also includes the reading of the CSV file with the age annotations. Each raw of the file includes, separated by a comma (according to the CSV standard), the filename of the sample (e.g. 000000.jpg) and the estimated age as an integer (e.g. 32). Therefore, an example of raw may be 000000.jpg,32. The file of the results will be formatted exactly in the same way. The provided sample test.py includes the writing of the results file.
The submission must be done by email. The archive file can be attached to the e-mail or shared with external links. We strongly recommend to follow the examples of code and report to prepare the submission.
The participants will receive an e-mail with their score on the test set. We strongly encourage the submission of papers to CAIP 2021 reporting the proposed method and the achieved results.
Results
Before the deadline, 20 teams sent an official request for participating to the contest from all over the world: 9 from Europe, 5 from Asia, 4 from North America, 1 from South America and 1 from Africa.
All the requests came from academia, except for one from a company. Finally, 7 teams submitted a valid method to the contest, reported in alphabetic order:
BTWG, CIVALab, GoF, GvisUleTeam, Levi, Pacific of Artificial Vision, VisionH4ck3rz. The papers of four Teams, namely BTWG, Pacific of Artificial Vision, CIVA Lab and
VisionH4ck3rz have been accepted and presented in the CAIP 2021 Conference. The paper of the contest is available here.
In the following table, the final ranking of the contest is reported:
| Rank | Team | AAR | MAE | $\sigma$ |
|---|---|---|---|---|
| 1 | BTWG | 7.94 | 1.86 | 0.20 |
| 2 | Pacific of Artificial Vision | 7.55 | 1.84 | 0.61 |
| 3 | CIVA Lab | 6.97 | 2.05 | 0.98 |
| 4 | Levi | 5.64 | 3.43 | 0.93 |
| 5 | VisionH4ck3rz | 5.41 | 2.89 | 1.70 |
| 6 | GoF | 3.80 | 3.23 | 2.97 |
| 7 | GvisUleTeam | 3.69 | 3.41 | 2.90 |
Organizer

Antonio Greco
Assistant ProfessorDept of Information and Electrical Engineering and Applied Mathematics (DIEM)
University of Salerno, Italy
Contact
Feel free to contact us for more information.
agreco@unisa.it
+39 089 963006